

Benefits of Fine-Tuning LLMs
Custom fine-tuning of large language models improves accuracy, consistency, and task-specific performance in production applications, and can deliver large reductions in latency and inference costs. OptimumPartner AI provides end-to-end AI fine tuning services for developers and product teams. We design datasets, fine-tune models, evaluate results, and deploy improvements safely into real-world applications. Based in the UK, we work with developers across English-speaking markets, including the US, Canada, and Europe, and regularly work US and European hours to support active development.

Our Services
Our AI Fine Tuning Services Include:
-
Fine-tuning large language models, including OpenAI and Llama for domain-specific tasks
-
Instruction tuning and response optimization
-
Changing LLM tone and behavior to suit your domain
-
Dataset design and preparation
-
Model evaluation and performance testing
-
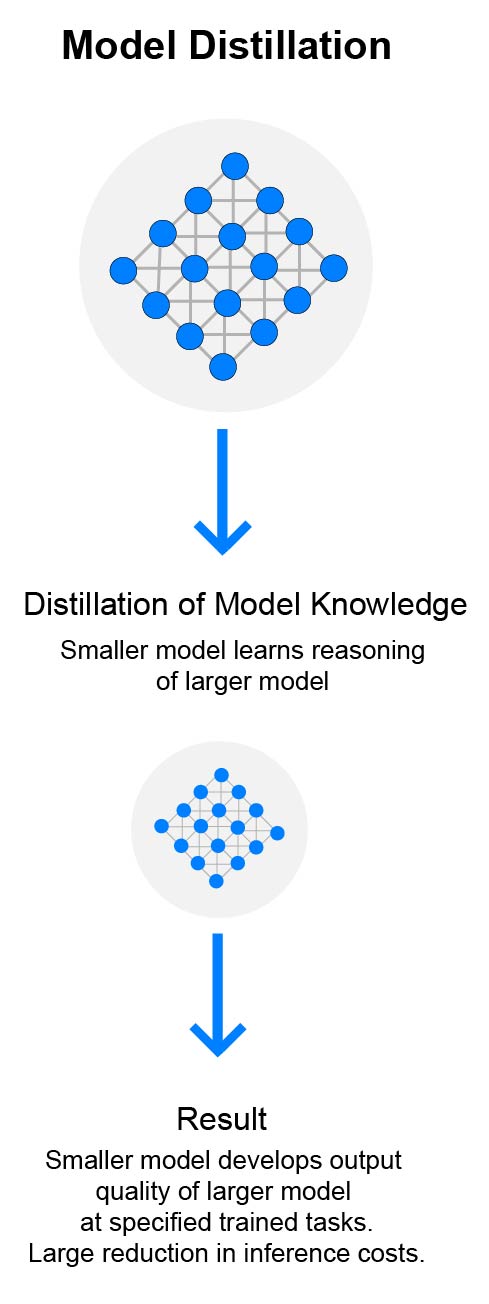
Model Distillation: Compressing large-model performance into smaller models for specified tasks, for faster inference and lower operating costs.
-
Prompt optimization and caching strategies to improve efficiency at scale
-
Deployment guidance and monitoring
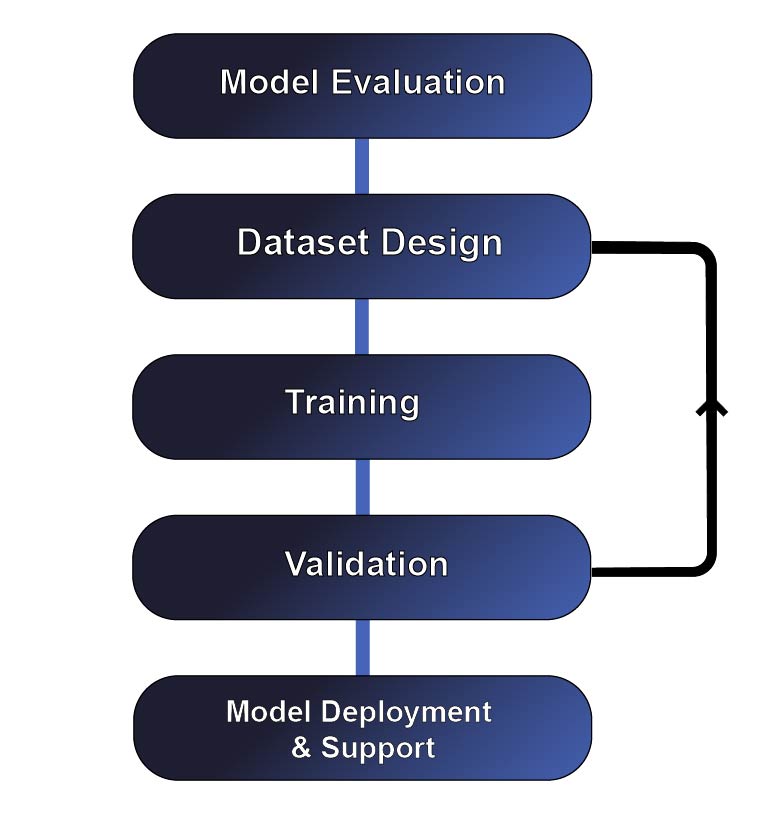
Our Fine-Tuning Process
-
Requirements & Use-Case Definition
We analyse your application, users, and desired model behavior. -
Dataset Design & Preparation
We create and clean training datasets aligned with your domain and intent. -
Model Fine-Tuning
We fine-tune AI models using best-practice configurations. -
Evaluation & Iteration
We measure improvements in accuracy, consistency, and relevance. This can include evaluating trade-offs between model size, cost, latency, and output quality. -
Deployment & Support
We help integrate the tuned model into your production environment.
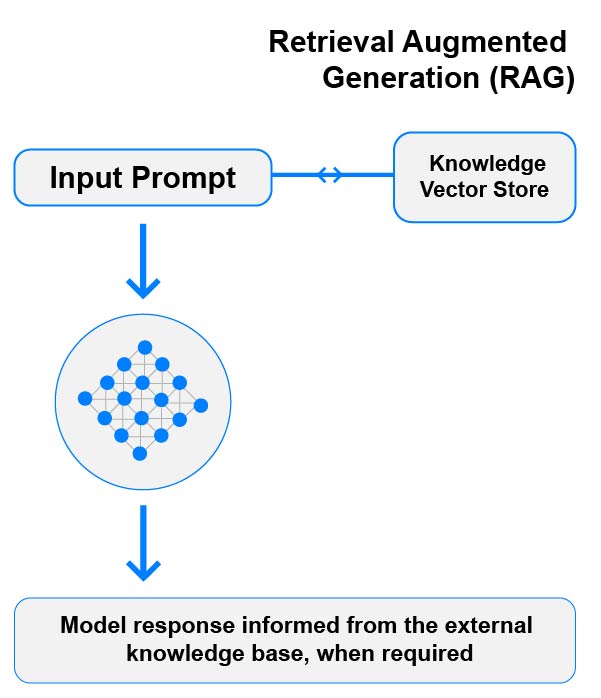
Fine-Tuning and Retrieval-Augmented Generation (RAG)
Fine-tuning and RAG solve different problems and are often used together.
Fine-tuning is best suited for shaping model behavior — such as instruction following, response structure, tone, and task-specific reasoning. RAG is used to provide models with up-to-date or proprietary knowledge at inference time.
In many production systems, a fine-tuned model is combined with RAG to achieve both consistent behavior and access to external knowledge. We help teams design architectures that use fine-tuning, RAG, or a combination of both depending on the application.
Who This Is For
-
SaaS teams building AI-powered features
-
Developers deploying AI models in production
-
Companies needing consistent, domain-specific outputs
-
Teams scaling beyond prompt engineering
Example Fine-Tuning Use Cases
The following examples illustrate common fine-tuning scenarios we see in production applications:
Example 1: Reducing Cost by Specialising a Model
You have an application that relies on a capable model to perform a specific, repeatable task. The outputs are correct and reliable, but the model is expensive to run and slower than you’d like for a high-volume production workload.
In this situation, we work with you to identify the exact behavior your application depends on and use a larger model to generate high-quality reference outputs across a representative set of real inputs. These input–output pairs are used to create a training dataset that captures the behavior of the larger model for that task. A smaller, more cost-effective model is then fine-tuned using this dataset to reproduce the same behavior in production. The result is a model that behaves consistently for the task your application needs, whilst reducing inference cost and latency.
Example 2: Aligning Tone and Output Format Across an Application
You have an application where the model is expected to respond in a specific way — using a consistent tone, following a defined structure, and presenting information in a format that works for your product. While prompt engineering can get you close, responses still vary depending on phrasing, conversation history, or how much context is provided.
In this situation, we work with you to review real outputs from your application and agree on what “correct” responses look like in practice. We then prepare a dataset that demonstrates the desired tone, structure, and formatting across a range of typical inputs. The model is fine-tuned to internalise these patterns so that the expected style and format become the default behavior, rather than something enforced through increasingly complex prompts.
This allows teams to simplify prompts and reduce repeated instruction tokens in production requests.
Example 3
Correcting Instruction-Following Failures in an Application
You have an application where the model is given clear instructions, but it does not always follow them reliably. In some cases it ignores constraints, answers the wrong part of a request, or includes information that the application explicitly asked it not to include. These failures are inconsistent, which makes them difficult to handle through prompts alone.
In this situation, we work with you to review real examples where the model fails to follow instructions and define what the correct behavior should have been. We then prepare a dataset that pairs representative inputs with the expected responses, reinforcing instruction adherence across common and edge-case scenarios. The model is fine-tuned so that following application instructions becomes the default behavior, rather than something that must be repeatedly reinforced in every prompt.
Quality Review & Feedback Workflow
To support fine-tuning and evaluation workflows, we provide a collaborative review system that allows clients to actively participate in the fine-tuning process.
During development, clients can review model outputs, test behaviors, and provide structured feedback that is directly incorporated into dataset refinement and iterative fine-tuning. This includes optional access to a lightweight iOS interface for reviewing responses, flagging issues, and communicating feedback in near real time.
This collaborative workflow enables continuous testing, faster iteration, and tighter alignment between the fine-tuned model and the application’s requirements throughout the project.
Talk to an AI Engineer
Discuss your use case and determine whether fine-tuning is the right approach. Visit our contact us page to submit some details about your project, or download the OptimumPartner AI iOS App to start a chat with our AI Team.
Company Snapshot
Registration UK # (13226975)